

Machine learning is a means of data analysis that automates analytical model building. It is a branch of artificial intelligence based on the idea that machines can learn from data, identify patterns and make decisions without any pre-programmed rules. In this article, we are going to cover some points:
- What is machine learning
- The history of machine learning
- Machine learning methods
But let’s go more in-depth on the definition..
What is Machine Learning?
“Machine learning is a computer program said to learn from experience ‘E’ with respect to some class of tasks ‘T’ and performance measure ‘P’, if its performance at tasks in ‘T’, as measured by ‘P’, improves with experience ‘E’.” — Tom Mitchell
The machine learning field is a quite vast and is expanding quickly. It continually partitions into subcategories and different types of machine learning. ML is an important aspect of modern business and research. By using algorithms and neural network models, it can assist computer programs in progressively improving their performance with minimal human intervention.
The same way that when humans are born being initially incapable of performing any useful function or task until taught over time, computers can learn in the same manner. As a simplified example, if you want to create a computer program that can learn to identify whether an animal is a dog or cat, you would feed it many images of dogs and cats. Eventually the computer system would be able to use statistical models based on previous data to identify whether it is looking at a cat or dog.
Machine learning algorithms are often categorised into several types. This article will cover four of the most common types of machine learning:
- Supervised ML
- Unsupervised ML
- Semi-supervised ML
- Reinforcement ML
But before we delve into those areas, lets first explore a brief history.
History of Machine Learning
Arthur Samuel, an American pioneer in the field of artificial intelligence and computer gaming, coined the term machine learning in 1959. While working at IBM, Samuel published a study in that year where he expressed a digital computer’s capability of behaving in such a way, “which, if done by human beings or animals, would be described as involving the process of learning”. He expressed the notion that, at the time, computers existed with adequate data-handling abilities to make use of machine-learning techniques, but were limited by mankind’s knowledge of these techniques.
Samuel developed a program that played checkers on a championship level using his basic checker-playing program. Using a tree-based decision making model, his program learned to play while recognising most winning and losing end positions many moves in advance.
Since the computer program had a very small amount of computer memory available, Samuel created what is called “alpha-beta pruning”. Alpha-beta pruning is an adversarial search algorithm used commonly for machine playing of two-player games such as chess, checkers, etc. It essentially stops evaluating a move when at least one possibility has been found that proves the move to be worse than a previously examined move.
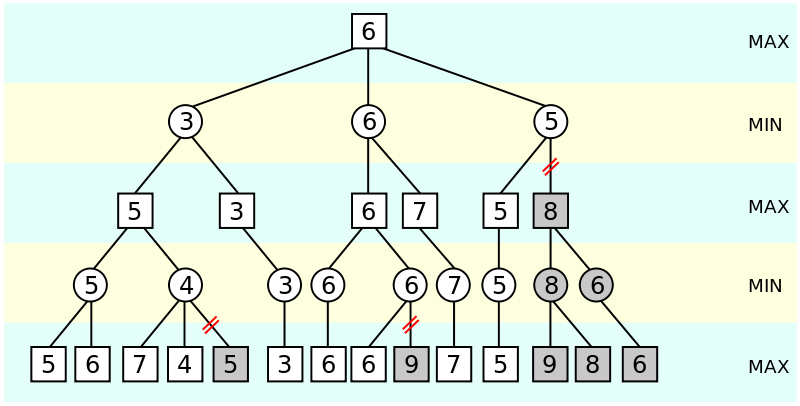
Figure 1: Alpha-beta pruning search algorithm illustration
Above we can see a simplified illustration of alpha-beta pruning. The greyed out nodes are ones that the program no longer considers to be explored. Moves are evaluated from left to right.
As a result of Samuel’s study, he concluded that it can be said with some certainty that it is possible to create learning algorithms that would greatly outperform an average person and would eventually be economically feasible to apply to real-world problems.
In 1961, Ed Feigenbaum and Julian Feldman were creating the first artificial intelligence anthology (computers and thought, 1961) when they asked Samuel to give them the best game that his learning program had ever played as an appendix to their anthology. Samuel took this opportunity to challenge the Connecticut state checker champion, ranked number four in the nation at the time, and won.
By the 1980’s and 1990’s, machine learning was reorganised as a separate field, branching off of artificial intelligence. The field shifted its focus away from approaches it had inherited from artificial intelligence and instead towards methods and models based from statistics and probability theory. The increasing availability of digitised information and the introduction of the internet helped ML research greatly.
Machine Learning Methods
Now that we’ve learned a brief history of machine learning, let’s explain the four main categories:
Supervised Machine Learning
This is an algorithm that can apply previously learned data against new data using labelled examples to make predictions of future events. In this algorithm, the results of the training are already known beforehand but the system simply learns how to get to these results.

Figure 2: Supervised Learning process
There are two tasks of supervised learning, classification and regression.
Classification – is the process of identifying to which set of categories an observation or data point belongs. Classification uses previous data and observations to determine which class to assign new observations. Labels are assigned to the new observation. An example is identifying animals from images (is this a dog or a cat?). Some applications in application include medical diagnoses, target marketing and banking.
Regression – models are used to predict a continuous numerical value. For example, predicting prices of a car given factors such as horsepower, size, etc, is one of the common examples of regression. It is a form of supervised machine learning and there are many types such as linear regression, logistic regression, decision tree regression, random forest regression, polynomial regression, to name a few.
Unsupervised Machine Learning
This is a ML algorithm in which a program is given a group of observations or data points and must find patterns or relationships within the dataset. Unlike in supervised learning, information used in unsupervised ML is neither classified nor labelled. This system is not used for finding out the correct solution but rather exploring a data set and draw inferences of its own.
Figure 3: Unsupervised machine learning process
Some of the most common algorithms used in unsupervised machine learning include:
Clustering – Cluster analysis is the task of grouping a set of observations or data points in such a way that objects in one cluster share more similarities than to those in other groups (clusters). It is a common technique for statistical data analysis and is predominantly used in pattern recognition, image analysis, data compression, and bioinformatics.
It should be noted that cluster analysis is not a single specific algorithm but rather a task that can be achieved by various algorithms. These algorithms can differ significantly in their defined parameters of what qualifies as a cluster. Different algorithms can have different approaches to identifying and grouping clusters, and different efficiency levels depending on the developer or computer program.
Figure 4: Cluster analysis
Semi-supervised Machine Learning
This type of machine learning is somewhere between supervised and unsupervised machine learning. This is because they use both unlabelled and labelled data for training – usually a small amount of labelled data and a large amount of unlabelled data. When unlabelled data is used in conjunction with a small amount of labelled data, it can produce a substantial improvement in machine learning accuracy.
Reinforcement Machine Learning
This learning method is one that interacts with its environment by producing actions and discovers errors or insights. This process of machine learning typically involves a lot of trial and error to collect data and determine the ideal decisions within a specific context. Simple reward feedback is required for the machine to learn which action is best.
Reinforcement learning is particularly favourable to problems that include a long-term versus short-term reward trade-off. Additionally, it is also used when there is little to no historical data about a problem because it doesn’t need information in advance.
This type of machine learning can be used in large environments in the following situations:
- Methods of collecting information about the environment are limited to interactions only
- Only a simulation of the environment is provided
- The model of the environment is known but there is no analytical solution available.
The downside of reinforcement learning is that it can take a substantial amount of time to train if the problem is complex.
Conclusion
There are several other machine learning algorithms but only the four most commonly used ones were covered in this article. We recommend reading up on our other articles with machine learning to gain a more in-depth understanding of the topic.